


It is still early for open-source AI
Despite all the recent action in the open-source AI space, we are still years away from unlocking its true potential

AI applications fall on a spectrum.
Some companies build applications on top of APIs, and some companies train their own models from scratch. Some fall in between, leveraging open-source models, perhaps even fine-tuning them further on their own data, or use the fine-tuning APIs provided by closed-source LLM providers.
No one knows for sure which approach will perform best in the long-term. Some predict a world where a few companies provide APIs that all other companies will end up using, while others predict that training will become so easy and ubiquitous that everyone will have their own model.
At this point in time, most successful AI companies either train models from scratch (Midjourney, ChatGPT, Character AI) or build on top of APIs (Jasper, Copy AI, Harvey). Fewer companies have launched successful products built on top of open-source models.
That said, there is a lot of optimism around open-source. With the leaked Google memo, the release of LLaMA 2 and other increasingly powerful models, and other amazing developments, there’s a growing sense that open-source in time will catch up to closed-source and then surpass it.
There are some strong arguments to be made. Model training is incredibly expensive and requires expertise that is hard to find and hire. It makes economic sense for companies to either build on top of APIs or skip the pre-training stage by grabbing an off-the-shelf open-source model. Between the two, open-source gives you significantly more control over your model and data.
In the long-term, I too am excited about open-source. Unfortunately, there are reasons why I think we won’t see significant adoption of open-source LLMs in applications for another several years. Past that point, it is still an open question whether open-source can catch up to closed-source.
Open-source AI faces challenges
A company that wants to build a product on top of an open-source model faces several challenges today. The first one is size.
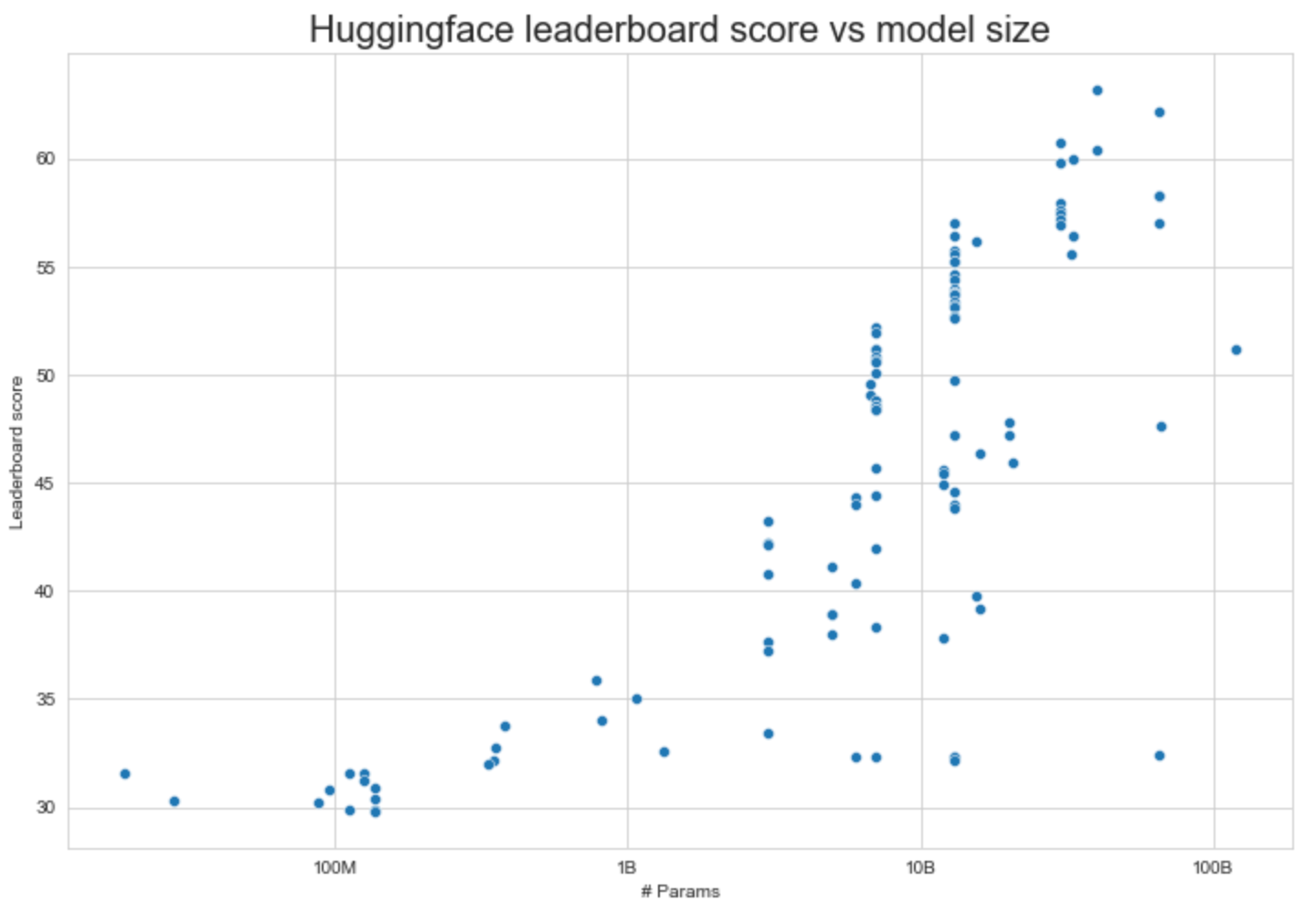
The open-source community focuses primarily on small models – on the order of 13 billion parameters or less. A few bigger labs have released models in the 30-70 billion parameter space, and BLOOMZ tops out at ~176B, but almost all of the fine-tuned variants of LLaMA are 13B parameters or less, as are most of the newly released models that have been trained from scratch.
Unfortunately, there is a reason that all of the top AI labs in the world have been focusing on growing model size – it is a prerequisite for performance. Training smaller models on more data helps up to a point, after which performance saturates, just as scaling laws predict.
The scaling challenge would be less of an issue if the performance of open-source LLMs at the smaller scales of 7 to 13 billion parameters was sufficient for the use-cases companies are considering, but unfortunately they are not. Small models don’t make for good chatbots, don’t automate workflows, and don’t generate working code beyond a function or two. This aligns with research on emergent abilities which finds that many skills only appear at larger scales of tens of billions of parameters.
There are certainly still use cases for models at this scale around basic prediction and text understanding, but they will not produce the revolutionary companies that we have been promised.
Of course, not all LLMs are small. LLaMA 2 (now Llama?) just came out, and although it certainly is a game changer, it still lags behind GPT-4 in performance, in particular on coding problems. It is impressive that Meta has been able to squeeze more performance out of Llama without increasing size much, but the gap between 1 and 2 is not much like that between GPT-3 and 4, which suggests they will need to scale up further to be competitive.
This leads us to the second challenge that open-source LLMs face: infrastructure. Training and serving LLMs is hard and expensive. Bigger models are disproportionally harder and more expensive. Models consume compute proportional to size but performance scales proportional to the logarithm of size. Bigger models also bring infrastructure challenges: training instability, node failures, communication bandwidth, etc.
Of course, the fact that there is demand and that technical solutions exist today means that the market will catch up and provide solutions eventually. MosaicML is only the beginning – there is still much to do around managed fine-tuning and serving. It will take time.
The fact that there is so much to do ties into the third challenge: customization.
Open-source vs closed-source
The key question is not whether open-source LLMs will advance, but rather whether they will catch up to closed-source APIs. Failing to do so probably means that they fall out of favor, leading to the aforementioned bifurcation of companies that either train from scratch or depend on APIs. After all, you can’t win a market with a categorically worse product.
Within the context of raw performance, open and closed-source LLMs have significant and contrasting advantages. Open-source moves faster and allows for more customization. Closed-source has an easier time dealing with large scale coordination, such as executing expensive training runs, and provides a better user experience. The resemblance here relative to classical open vs closed-source software is rather conspicuous.
At this point in time, closed-source LLMs have the advantage for precisely the two reasons mentioned above – they have produced better models and have made it easier for both users and developers to access their powers. In order to catch up, open-source either needs to prove that openness leads to better quality models, or that it can produce a better developer experience.
For the most part, OpenAI is crushing the developer experience. They provide fine-tuned models for chat, embeddings, function calling, image generation, voice-to-text, packaged with great documentation and pretty good latency and uptime. It seems unlikely that open-source will surpass them anytime soon.
No, the way that open-source competes with closed-source is by allowing for greater customization, which will enable medium-sized tech companies to customize their LLMs specifically for their needs. GPT-4 API calls everywhere will be replaced by custom, fine-tuned models tailored to each industry and customer.
This leads us to the third challenge – almost none of the tools you need to customize LLMs (to a degree that they outperform GPT-4) exist today. There are hundreds of open-source tools that have yet to consolidate, and although they are all promising, they are all also very fresh, filled with bugs, and often lack critical features. Furthermore, the set of people in the world that can utilize the benefits of open-source LLMs is small and hard to access, and they are probably more likely to want to work for closed-source LLM API providers anyway.
What the future holds
Now, that’s enough bashing for today. We are still early, and I am confident that open-source will surpass the challenges I mentioned. What worries me is not whether open-source will improve, but rather whether it can catch up to OpenAI.
I am in the category of people that believe that LLM quality still has a long way to go (if you disagree, try to build even a remotely complex multi-LLM-call workflow, even using GPT-4), and so for a long foreseeable future, having the best LLMs will matter a ton for adoption. OpenAI is ahead of the pack, and although there is a lot of diversity in open-source, the peak remains solidly behind.
My sense is that a lot will depend on the biggest research labs, in particular Meta. As far as I know, no other lab has the resources, infrastructure, and talent to match GPT-4, while simultaneously having demonstrated the motivation to be willing to give such a model away for free.
The reason open-source needs these mega labs is that open-source by itself likely won’t be able to attract the funding necessary to pre-train models at the scale of GPT-4 and beyond, and without pre-training, none of the incredible advances in fine-tuning and quantization that we have seen from the open-source community matter.
In the long run, I think both open and closed source models will find their niche. Eventually, both will progress far enough that they find tons of use cases, and different companies will build on different platforms depending on their needs and resources. Closed-source will probably remain ahead in terms of raw performance and developer experience, but once open-source + industry figures out how to make fine-tuning 100B+ parameter LLMs feasible for mere mortals, open-source will finally unlock their key differentiating advantage: customization.
At that point, I think the balance will shift, and we will see more different kinds of LLMs. Or at least I am hoping for it, since a world with tons of LLMs is more exciting than a world with only a few ones. It will take time to get there though, and that time is proportional to how much big labs are willing to spend on models that they then give away. These decisions are up to a handful of individuals, so it is hard to say how things will play out. For now, we can just sit back and wait.